やりたかったことをようやくみつけたのでリンク貼っとく
gasp使い方
とりあえずざっくりコード
import {gsap} from "gsap";
import { useEffect, useRef } from "react";
import ScrollTrigger from "gsap/src/ScrollTrigger";
/** @jsImportSource @emotion/react */
import { css} from "@emotion/react";
export default function Top() {
useEffect(() => {
gsap.registerPlugin(ScrollTrigger);
// 各画像要素のアニメーション
const scrollphotos = gsap.utils.toArray(".scrollphoto");
scrollphotos.forEach((el) => {
const tl = gsap.timeline();
ScrollTrigger.create({
trigger:el,
start: "top center",
end: "bottom center",
once: true,
onEnter: () => {
const h3element = el.querySelector('.scrollphoto-title');
gsap.fromTo(h3element, {width:"0", overflowX: "hidden"}, {width:"200px", delay:1.5, duration:2});
popup(el);
}
});
function popup(el) {
tl.fromTo(el, {x:-1000, autoAlpha:0}, {x:0, ease:"boue.inOut", duratioin:1.5, autoAlpha:1})
}
}, []);
const tl2 = gsap.timeline();
tl2.to('.my-element2 span', {x:100, ease:"bouce.out", fontSize:'2.5em', duration:2})
});
return (
<div css={wrapBox}>
<div className="my-elemtent2" css={fontBox}>
<span>Hello,world</span>
</div>
<div className="scrollphoto" css={scrollphoto}>
<h3 className="scrollphoto-title" css={photoTitle}>Photo1</h3>
<img src="images/card-1.webp" alt="" />
</div>
<div className="scrollphoto" css={scrollphoto}>
<h3 className="scrollphoto-title" css={photoTitle}>Photo2</h3>
<img src="images/card-2.webp" alt="" />
</div>
<div className="scrollphoto" css={scrollphoto}>
<h3 className="scrollphoto-title" css={photoTitle}>Photo3</h3>
<img src="images/card-3.webp" alt="" />
</div>
</div>
)
}
javascriptでいろんな要素を取得するとりあえずの一覧
ざっくりとDOM要素の取得関数一覧。
querySelectorとquerySelectorAllでほぼ大丈夫だけど ページ数が多かったりするときはgetElementBy... の方が処理が早いのでいいらしい。
詳細の要素を指定したい場合などはページ数が多くても併用する。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
</head>
<body>
<h1>h1タイトル</h1>
<p id="pId" class="Attr">段落<span>スパン</span></p>
<p class="Attr">段落2<span>スパン2</span></p>
<p class="Attr">段落3</p>
<input type="text" name="nameAttr">
<input type="password" name="pwdAttr">
<script>
const pid = document.getElementById("pId");
console.log(pid);
const getClassAttr = document.getElementsByClassName("Attr");
console.log(getClassAttr)
const getPAll = document.getElementsByTagName("p")
console.log(getPAll)
const getNameTypeText = document.getElementsByName("text");
const getParentSpan = document.querySelector("span");
const getParentSpan2 = getParentSpan.closest("p")
const getH1broTypePass = document.querySelector('h1 ~ [name = "pwdAttr"]');
const getChildpId = document.querySelector('#pId > *')
const getNextText = document.querySelector('input + [name="text"]');
console.log(getNameTypeText)
console.log(getParentSpan2)
console.log(getH1broTypePass)
console.log(getChildpId)
console.log(getNextText)
</script>
</body>
</html>
取得したHTMLを表示・編集などする
console.log(getPAll[1].innerHTML) console.log(getPAll[0].textContent)
javascriptで外部からデータをfetchで取り込む
jsonなどのデータを取り込んで処理していくのはfetch
<script>
fetch("sample.json")
.then( response => response.json() )
.then( data => {
for (const {key,value} of data) {
console.log(key + ":" + value);
}
});
// awaitを使った場合
async function myFetch() {
const response = await fetch("sample.json");
const data = await response.json();
for (const {key, value} of data) {
console.log(key + ":" + value)
}
}
myFetch()
</script>
sample.json
[
{"key": "apple", "value": "リンゴ" },
{"key": "orange", "value": "オレンジ" },
{"key": "melon", "value": "メロン" },
]
DAY45 Beautiful Soupを使ってスクレイピングをする
Beautiful Soupを使ってスクレイピングをする
目次
概要
今回はrequestsとBeautiful Soupというプラグインをインポートしてウェブサイトのデータを取得するスクレイピングの簡単な部分を勉強します。
簡単に言えばpythonでサイトのソースを保存して、欲しいところだけクリッピングができるということ。
例えばそのサイトのリンク先だけ保存するとか、画像リンクだけを取得するとか。
それでは始めます。今回は結構簡単ですが、HTMLをある程度理解していることが前提です。
requestsとBeautiful Soupをインストールして呼び出す
1ページのみなら、使い方は一度さらえばとても簡単。
import requests
from bs4 import BeautifulSoup
re = requests.get("https://news.yahoo.co.jp/topics/business")
page = re.text
soup = BeautifulSoup(page, "html.parser")
titles = soup.find_all("div", {"class":"newsFeed_item_title"})
for title in titles:
print(title.text)
例えば、このコードでは
ここのタイトルリストを表示されている分を取得しています。
- requests.getにurlを入れてソースを取得
- re.textにすることでオブジェクトからテキストに変換
- soupという変数でBeautiful Soupを呼び出し、pageの変数をhtml.parserという機能で解析する
- 解析したhtmlからfind_allという機能でhtmlソースのnewsFeed_item_titleというクラスを持つdivを全部抽出し、titlesという配列で保存
- titlesの配列から1つずつprintでコンソールに出力
という流れです。
基本的にはこれがテンプレな感じでスクレイピングができますが、 普通は複数のページとかやりたいのでその辺はまた後日勉強していきたいと思います。
よりわかりやすいサイトはこちらとか
図解!Python BeautifulSoupの使い方を徹底解説!(select、find、find_all、インストール、スクレイピングなど) - AI-interのPython3入門
DAY38 pythonでデータをトラッキングしてGoogle sheetsにまとめる!
PythonとAPIを使ってGoogle Sheetsを連携した作業を学ぶ
目次
2つのAPIを使って何をしたかをデータでまとめる
コンソールにその日に何のエクササイズをしたかを答えるだけでこんな感じでAPIが数値を判断してGoogle Sheetに入力してくれます。 カロリーまで入力してくれる! Nutritionist のAPIを使います。
nutritionix_apiを利用してエクササイズのカロリーを出力してもらう
nutritionixのサイトへいき、freeを選んでIDとAPI keyを取得します。
pythonのプロジェクトのmain.pyと同じ階層に.envを入れて、API KEYとIDを入力しておきます。
.env
ENV_NUTRITION_ID = "iddayo"
ENV_NUTRITION_KEY = "keydayo"
python-dotenvのパッケージをインストールしてから、読み込みをします。
テンプレはこちら
import os
from dotenv import load_dotenv
from os.path import join, dirname
load_dotenv(verbose=True) #.envファイルが見つからない時にエラーを出す
dotenv_path = join(dirname(__file__), '.env')
load_dotenv(dotenv_path)
次にnutritionのドキュメントを見ます。
今回はエクササイズを入力したいので、 エンドポイントは/v2/natural/exerciseになります。

みる感じ
x-user-jwt →apiのidとkeyがheaderとしている query → 質問内容を文章にする gender,weight_kg,height_cm,age 性別、体重、身長、年齢
がいるようなのでこれらも変数定義しておきます。
apiを読み込むときはrequestsがいるので、先にpackageでインストールをするのを忘れずに。
Nutritionix API v2 - Documentation [PUBLIC] - Google ドキュメント
ここのObtaining API Keys & Authenticating部分をみると、 apiのIDとKEYはデータを送信するときは x-app-id、x-app-keyと名付けて入力するとのこと。(gender : 30,みたいに x-app-id: ID という感じ)
あと同じページでExcecise Endpointsをみると、requestはpostにするとのことなのでこれらを理解してからコーディングすると
import requests
import os
from dotenv import load_dotenv
from os.path import join, dirname
load_dotenv(verbose=True) #.envファイルが見つからない時にエラーを出す
dotenv_path = join(dirname(__file__), '.env')
load_dotenv(dotenv_path)
GENDER = "male"
WEIGHT_KG = 56
HEIGHT_CM = 168
AGE = 27
NUTRITION_ID = os.environ.get("ENV_NUTRITION_ID")
NUTRITION_KEY = os.environ.get("ENV_NUTRITION_KEY")
NUTRITION_ENDPOINT = "https://trackapi.nutritionix.com/v2/natural/exercise"
def get_nutrition_data():
exercise_text = input("何のエクササイズを何分した?英語で(e.g. ran 15min, swam 30min, walked 1hour): ")
headers = {
"x-app-id": NUTRITION_ID,
"x-app-key": NUTRITION_KEY,
}
parameters = {
"query" : exercise_text,
"gender": GENDER,
"weight_kg": WEIGHT_KG,
"height_cm": HEIGHT_CM,
"age": AGE,
}
r = requests.post(NUTRITION_ENDPOINT, headers=headers, json=parameters)
result =r.json()
print(result)
get_nutrition_data()
こんな感じになります。
試しにこれを起動させてみると、

こんな感じでjsonデータを吐き出してくれます。 今回は45分走ったと答えると大体500kcalくらいの消費になるようですね。
Sheetyを利用してSpreadSheetを連携する
sheetyを利用する前に先にスプレッドシートを作っておきます。 表はこんな感じ。

シート作成後にsheetyというサイトへ行き、googleアカウントと連携します。
プロジェクトを新規で作って、スプレッドシートのURLを入力するとこんな感じで読み込んでくれるので、Create Projectをクリック。

そうすると、APIのエンドポイントがGET、POSTなど別に表示される。 URL自体は同じだけど、記述方法はGETとPOSTで少し違うので注意。
GETの場合はデータを拾ってくるだけなので認証のみでよい感じだけど、POSTはどこのセルに何を入力するなど細かい設定も記述しなくてはいけない。
まずはGETを起動して動作するか確認してみる
nutrition apiと同じような感じで、まずはシートのデータを取得する機能を作ってみる。
SheetyのAuthenticationを設定して、Tokenも適当に入力すると、下のAuthorization Headerというところが変わる。ここをheaderを定義していれる。
SHEET_ENDPOINT = "sheety no url dayo"
def get_sheets_data():
headers = {
"Authorization": "Bearer tokendayo"
}
r = requests.get(SHEET_ENDPOINT, headers=headers)
result = r.json()
print(result)
とこんな感じになる。
POSTで書いてみる
GETで無事データが取得できたので、POSTでも書いてみる。
今回はDate,Time,Exercise,Duration,Caloriesの5項目を入力するので、配列でフォーマットを作る。
また、最初に作ったget_nutrition_data()は複数のエクササイズを1度に入力できるので、その度に入力できるようにfor文を使う。
def put_sheets_data():
result = get_nutrition_data()
result = result["exercises"]
for exercise in result:
sheets_params = {
"workout": {
"date": today,
"time": time,
"exercise": exercise["user_input"].title(),
"duration": exercise["duration_min"],
"calories": exercise["nf_calories"]
}
}
re = requests.post(SHEET_ENDPOINT, headers=headers, json=sheets_params)
print(re.text)
最初に作ったget_nutrition_data()からjsonデータを取得して、
そのjsonから抜き出したい階層まで移動してからパラメーターを作っています。
for文を使うことで["exercises"]配列から1データずつを入力することで、
ranは15分、カロリー
walkedは14分、カロリー
とスプレッドシート1行ずつに入力することができます。
gitはこちら。
Gitをさらっとまとめてみる
目次
Gitとは
自分1人でページの更新や運営をする分にはあんまりいらないのかもしれないが、複数人で1つのプロジェクトの更新や運営をすると必ず発生するファイルの入れ違いアップロードとかを防ぐために差分だけを更新してくれたり、誰がいつどこを更新したかを全て記録してくれるツール。
index.htmlを複数人で編集してもGitで管理してからFTPとかに上げていくことで安全に更新ができる。
また、運営しつつ新しい機能を追加したい時とかには機能追加用のコード編集場所を作って、運営中のコードを傷つけずに機能追加コードをいじることができたりする。
機能追加コードを触っているうちに運営中のコードに戻りたい!という時も運営中の編集場所にもどればコードが運営中のコードに戻ってくれたりもする。
プログラマーでは実務で必須なので簡単にでも勉強しておかないといけない。
詳しくはこちら。
ログイン
Gitは基本的にネットでソースを共有するので、そのソースの保管場所を提供してくれるサービスを使わなくてはいけない。
そのサービスで有名なのがGithubとBitbucket。
違いはいくつかあるが勉強用で使うのであればどちらでもいい気がする。
今回はBitbucketでやってみる。
特に難しいことはなく、メールアドレスかGoogleからログインなどすればすぐにサインアップができる。
自分のページができるが、ここのページでどうこうすることはなく、次に紹介するソフトで自分のPCとBitbucketのリポジトリを見やすく管理していく。 リポジトリとはそのプロジェクトのコードの貯蔵庫という意味。 OSでいえば単純にフォルダみたいな感じ。
プロジェクトフォルダ(PC)←これがローカルのリポジトリ
- 運営中のコードフォルダ ←ついでにこれがブランチという
- index.html
- product.html
- 機能追加のコードフォルダ ←ブランチ
- index.html
- product.html
- 運営中のコードフォルダ ←ついでにこれがブランチという
プロジェクトフォルダ(クラウド) ←これがリモートのリポジトリ
- 運営中のコードフォルダ ←ブランチ
- index.html
- product.html
- 機能追加のコードフォルダ ←ブランチ
- index.html
- product.html
- 運営中のコードフォルダ ←ブランチ
こんな感じで考えたらいいかと思う。
SourceTreeインストール
次にSourceTreeをインストール。
まず下のURLの右上のボタンをクリックして
同意すればダウンロード。
インストールしたら、まずメニューから設定をクリックし、
アカウントタブをクリック。認証方法はOAuthで。
追加をすれば先ほどのbitbucketのページに行ってからSourcetreeに戻ってくるので、それでアカウント追加完了。

アカウントが追加されたので、次にリモートリポジトリとローカルリポジトリを接続する。
Sourcetreeの小さいメニュー画面の中に「新規...」というのがあるので
それをクリックし、リモートリポジトリを作成。

またウィンドウが出てくるので、リポジトリの名前をつけて作成をクリック。

そうすると、さっきログインしたbitbucketでリポジトリが作成されている。

リモートボタンをクリックすると、こちらにもリモートリポジトリが追加されていることがわかる。 ローカルをクリックしてもまだ何もないので、リモートリポジトリをコピー(クローン)する。
sourcetreeのリモートタブにあるリポジトリの行のクローンというのをクリックすると、どこにローカルリポジトリを置くか設定してクローンができる。

これは後々フォルダ移動はできない?(できるかもだけどめんどくさそう)なのでちゃんと決めてからクローンする。間違えた場合はフォルダを移動ではなく削除してからクローンしなおす方が簡単。
クローンが終わると、こんな大きめのウィンドウが出るので、これで準備が完了。
他の人のGitをクローンして試すこともできたりするので、
ローカルから先に作って変更後にリモートリポジトリを使うこともできるけどリモートを先に作ってクローンの方を馴染ませといた方がいいのかもしれない。
コミット・プッシュ・プル
Gitでまずなにそれ?と思ったのはこの3つの言葉。 WEBデザインとかでは聞いたことなかったので全然馴染みがない。
簡単にいうとこんな感じかと思う。
プル
他の人がコードを更新したものを自分のPCのリポジトリ(ローカルリポジトリ)に差分を更新することで最新のデータにすること。1日のはじめに作業する時とか、こっちが更新する前とかに一旦プルをしておく習慣をつけるとよいと思う。
コミット
自分が変更したコードをローカルリポジトリに記録すること。コミットをすることでSourcetreeでは変更前と変更後が見やすく表示されてわかりやすい。どこを変更したかなどコミットする際にはコメントが必須。
プッシュ
コミットしたコードをリモートリポジトリに送ること。プッシュされると他の作業している人にも変更がわかる。
何回も変更をプッシュしたりすると履歴が増えて荒れるのでプッシュは1日の作業の終わりとか、機能の追加が完了してからなど区切りの時にプッシュをする。
プロジェクトの作成の流れ
プロジェクトを始める時とかのざっとした流れをはこんな感じかと思う。
- Githubとかに置いてあるプロジェクトのリポジトリをローカルにクローンする。もしくはクローンされていたら最初にプルをしてデータを最新にする。
- 初めて作業するなら作業用のブランチを作成する。 すでに作業用のブランチが他の人に作られていて、自分が途中から入る場合にはそのブランチに移動する。(これをチェックアウトという。チェックインじゃないんかい!と思うけどチェックイン=コミットらしい)
- 作業を開始する。
- 作業が完了したり一区切りしたらコミットをする。
- コミットに特に問題がなければプッシュをする。
- 1に戻る
人によってはいくつかのブランチを行き来して開発していたりするのかも。
実務ではいきなりGit全般任されるとかはないと思うので、
最初はブランチ・プル・コミット・プッシュの流れだけわかってればGitに関しては迷惑かけないと思う笑
ただ間違えてコミットしちゃったとか、プッシュしちゃったとかあるので、そういうのがないように気をつける。
Gitの練習
ということで一旦簡単にGitの練習をしてみる。

sourcetreeの大きいウィンドウの真ん中にあるFinderで表示をクリック(mac使用)
gitのローカルリポジトリのフォルダに移動するので、そこに例としてhtmlのサンプルをダウンロードして保存する。
サンプルはこちらからダウンロードした。
そうすると、Sourcetreeが保存したファイルで埋め尽くされる。

これを一旦全部チェックをして、下のコミットメッセージに「first commit」と入力してコミットをする。
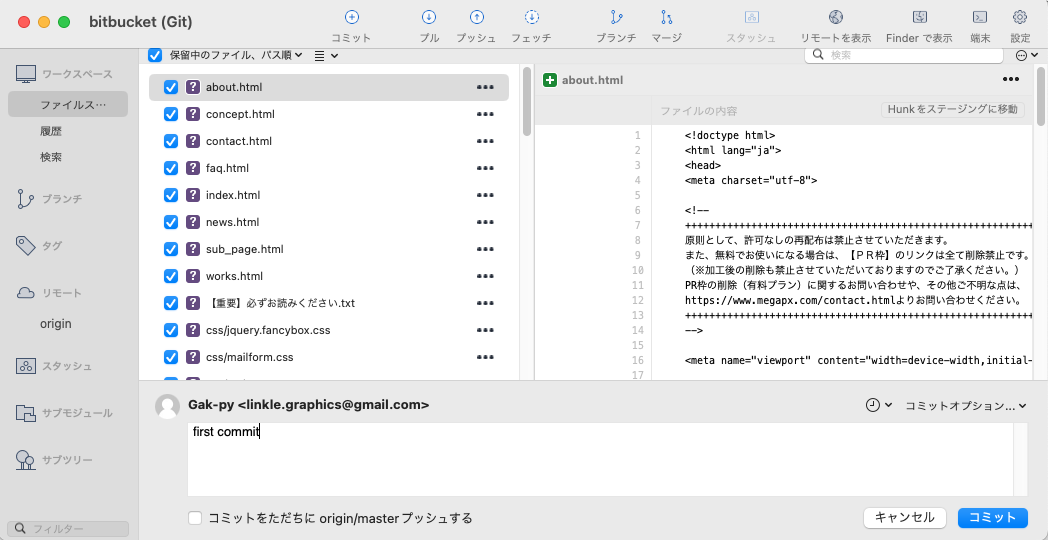
するとまた何もないウィンドウになるが、履歴をクリックするとコミット内容が表示される。

特に問題がなければプッシュをクリックする。 プッシュするブランチのmainにチェックを入れてOKで完了。

無事プッシュができた。mainというのはローカルリポジトリのmainブランチ、ということでorigin/mainというのはリモートリポジトリのmainブランチということ。

bitbucketのサイトも念の為確認してみると、こちらでもファイル確認できる。

次に、index.htmlを適当に変更してからSourcetreeをまた見てみると、
変わったコードが自動的に表示される。
変更前と変更後が表示される。

タイトル変更とコミットメッセージを入力して、コミット。
そうすると、履歴かmainブランチで新しい行が追加される。
現状はmainブランチで1コミットがまだプッシュされていない状態と表示されている。

他の人も同じ作業をしている可能性とかも考えてプッシュをする前にも念の為プルをしておいた方がいいかもしれない。
(たしか同じ作業を他の人がしていたらエラーが起きるはず)
プルして問題なく、プッシュを押すと完了。

mainタグとorigin/mainタグが一番上に移動している。
これはローカルリポジトリもリモートリポジトリもここが最新のデータ状態ですよということを表している。
Gitはそんなに難しくない
こんな感じで進めていくので、思ったより難しくないのであまり身構えないでも大丈夫そう。 頻度も多くないし万が一間違えてプルしちゃったとかでもキャンセルする方法はあるのでまたこれはこれでまとめて忘れないようにする。
入門はこれがわかりやすい