前回の記事の続きで
成形したグラフをグラフなどで可視化する流れを復習。
- import pandas as pdでpandas インポート, pdで呼び出せるように
- df = pd.read_csv('csvファイル', names=["見出し名1","見出し名2","見出し名3"], header=0) で見出し付きの表を作る。トップに必要のない見出しなどある場合はheader=0でなくす
- データの中に日付がある場合でタイプがstrの場合は、pd.to_datetime("見出し名")で日付の型に変更ができる。途中NaNなどが入っていたりうまくいかなくてエラーになった場合は、pd.to_datetime("見出し名" , errors='coerce')をつけると最後まで動いてくれる
- 現在の表の列を見出しにして表を再成形したい場合は.pivotを使う。
reshape_df = pd.pivot("見出し名1","見出し名2","見出し名3").fillna(0)
これで行見出しは見出し名1、列見出しは見出し名2になる。
NaNはfillna(nanの代わりに入れたい値)でNaNを差し替えできる。 - 表として出力したい場合は、plotを使う。
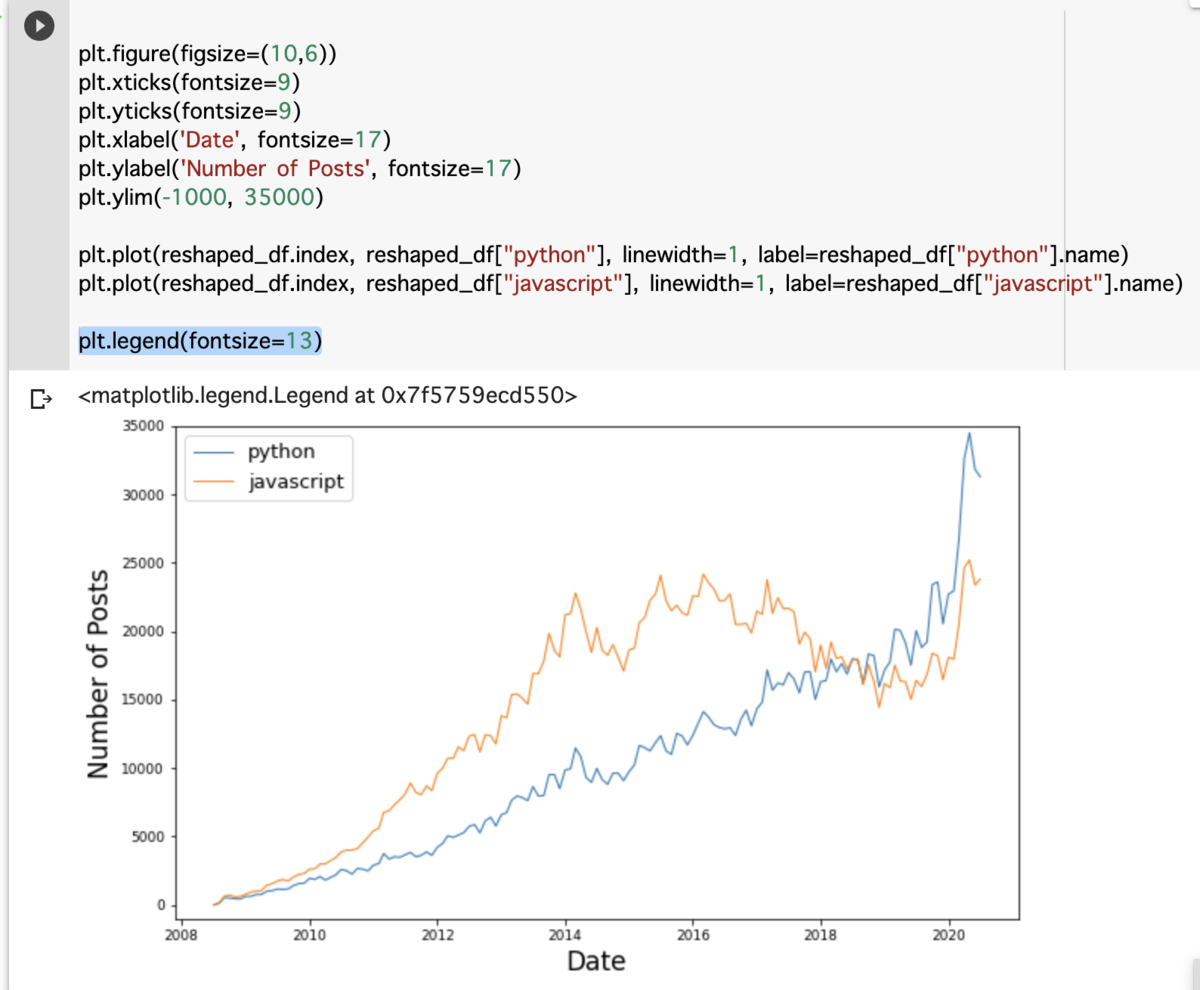
import matplotlib.pyplot as plt でインポートするとpltで呼び出せる。 - pyplot で出力する時の標準設定は
plt.figure(figsize=(10,6)) x軸、y軸のサイズを設定(10,6のところ)
plt.xticks(fontsize=9) x軸に設定されているデータのフォントサイズ
plt.yticks(fontsize=9) y軸に設定されているデータのフォントサイズ
plt.xlabel('Date', fontsize=17) x軸の見出しを作成(Date部分)・文字サイズ設定
plt.ylabel('Number of Posts', fontsize=17) y軸の見出しを作成(Date部分)・文字サイズ設定
plt.ylim(0, 35000) y軸数値の最低値・最高値の設定(-も可能) - 単一のデータを出力する場合は
plt.plot(reshaped_df["入手したいデータの見出し"], linewidth=1,)
できる。linewidthは線の太さを調整できる。
また、同じ表の複数のデータをグラフ化したい場合は、forで繰り返すと簡単。
for column in reshaped_df.columns:
plt.plot(reshaped_df.index, reshaped_df[column],
linewidth=1, label=reshaped_df[column].name) - 複数のデータをグラフ化する場合、データごとに色分けは自動的にされるけどどの色がどのデータかがわからない。
その場合はlegendを使うことでそれぞれの色を label = reshaped_df[column].nameで設定されたもので表示してくれる。
plt.legend(fontsize=13)フォントサイズも変更できる。